一、前言
早先,咱们的吃瓜网站部署在局域网里,通过谷歌代理穿透内网的方式对外提供服务,那时网站速度极慢,10秒内有响应算正常。毕竟浏览器的请求先到达美国洛杉矶,再绕道回中国大陆,经过联通线路抵达局域网,速度慢是肯定的。
后来,我们启用CDN,让主域名指向阿里CDN,源域名仍是通过穿透指向局域网。此时,热点的url速度较快,而冷门url的响应速度和以前一样慢。
再后来,为了解决冷门url的问题,网站从局域网搬迁至阿里云,此时网站总体响应速度提升至2~3秒。
再后来,CDN提供HTTP/2的能力,所以咱们立马申请一个免费SSL证书,强制HTTPS之后接着启用HTTP/2。开启HTTP/2以后,网站响应速度从几秒缩减至几百毫秒。(注:后来网站中加载大量第三方的插件,整体速度慢下来,此事略开不讲)
有好奇好问的同学说了:”那你这个HTTP/2有什么神奇的地方,速度怎么提升的?”咱们这一节就来探究该问题。
二、HTTPS
使用HTTP/2的前提是开启HTTPS,咱们先来看看HTTPS的原理。在深入HTTPS之前,咱们先回顾HTTP协议。
2.1 HTTP协议
HTTP协议是建立在TCP协议之上的典型文本协议,怎么样才能最简单地理解HTTP协议呢?我个人觉得,你可以想象由你来设计一个网络传输协议,你会怎么做?
最基本的,数据能从一台机器传输到另一台机器,这个由TCP协议保证,TCP可以把数据从源IP+源端口发送到目标IP+目标端口。如果要实现域名访问,可以借助DNS协议来获取的IP。
数据传给对方,对方怎么识别数据内容呢?思路是在数据前面的部分指出该次数据传输对应的方法和状态(状态行),后面接着该次请求的一些附加属性,比如让对方知道自己用的客户端和数据格式(请求头),最后的具体的数据,比如你要传输的文本(请求体),继续往下细想,我们差不多能自行设计出一套HTTP协议。
a) 特点
无连接:HTTP/1.1之前默认没有长连接,请求发送出去,收到响应之后立刻断开连接;(从HTTP/1.1开始,默认长连,也不太符合无连接的)
无状态:请求发送时并不会记录状态,也不会受上一次发送结果的影响(这意味着在实现上简单)。
灵活:允许传输各种类型的数据(问题来了:是怎么传输一个文件的?boundary分区)
b) 状态行
在请求时,状态行中有请求方法、请求资源URI、版本。
在响应时,状态行中有版本、状态码、状态说明。
关于状态码,1xx意味着服务器接收到请求后续再处理,2xx表示成功,3xx表示重定向,4xx表示客户端问题、5xx表示服务端问题,吃瓜群众在开发工作中常遇到的状态码有以下这些。
| 状态码 | 原因说明 |
|---|---|
| 200 | 成功表示 |
| 301 | 永久重定向 |
| 302 | 临时重定向,RFC协议中要求post请求收到302状态码时,不能自动重复发起post请求。而浏览器大多从Location获取URI,另外发起get请求 |
| 303 | 临时重定向,HTTP/1.1新增,允许浏览器将post转为get的行为 |
| 304 | 缓存,服务器向客户端说明,资源并没有发生变动,可以使用缓存 |
| 307 | 临时重定向,HTTP/1.1新增,再次声明,在post收到307响应时必须等待用户确定 |
| 400 | 请求无效 |
| 401 | 尚未认证,一般是没有做BA认证 |
| 403 | 禁止访问,一般是开启https之后,禁止用http协议访问 |
| 404 | not found,一般是访问路径错误,或服务器spring等路由映射异常 |
| 500 | 服务器内部异常,比如服务器内部出现NPE |
| 502 | 网关错误,一般是上游服务器主动关闭与网关之间的连接 |
| 503 | 服务器超负荷,这种错误极其少见 |
| 504 | 网关超时,一般是网关主动关闭与上游服务器之间的连接 |
c) 请求头/响应头
也就是俗称的header,在header中可以添加任意的key-value,这里讲几个有意思的header。
contentType
这个属性指出请求体/响应体中的数据格式,比如说是html格式、json格式、或是二进制流。如果要上传文件,则contentType须设置为”multipart/form-data; boundary=—————————分区标识符xxxxx”,服务器接收到之后再按分区读取数据流。
host
HTTP/1.1版本加入。http本身基于tcp协议,所以对http协议来说只需要拿到服务器的IP即可建立连接。但是,后来的虚拟机技术允许一台机器上搭建多个网站,每个网站的域名不一样,如果仅仅通过IP建立连接,客户端是无法成功连上某个网站的,所以人们增加host属性,指定该IP对应服务器上的域名网站。
transfer-encode
如果值是chunked,则意味着分块传输。在持久化连接中,客户端每次仅接收一部分内容,可谓是细水长流(每块格式是length+data,长度为0的块表示发送完毕)。在github以zip包的形式下载代码时,便是使用分块的方式下载,我们看不到下载进度。
d) 请求体/响应体
即发送/接收数据正文,不展开细述。
e) HTTP/1.1特性
长连接(可以模拟服务端推送)、
流水线管道(若干请求排队串行化)、
分块传输、
断点续传、
更强的缓存控制(CDN得以强大)。
2.2 HTTP协议缺陷
HTTP协议设计之初,并未考虑到安全,它主要会出现3种问题:被嗅探监听、内容被篡改、中间人攻击。
2.3 HTTPS修复安全缺陷
为了解决安全问题,HTTPS在HTTP协议与TCP协议之间增加SSL层(现在是TLS但大家习惯称SSL),依靠SSL层做加密工作,所以HTTPS协议的格式和HTTP协议是一样的,同样拥有状态行、请求头和请求体。
HTTPS工作原理示意图如下:
a) 防篡改
数据经过网络软硬件时,有可能被恶意篡改。HTTPS使用摘要技术(MD5/SHA等)来防止篡改,比如在发送数据时,对消息正文进行摘要计算,发送给服务器,后者再进行校验。防篡改本身属于数字签名技术
b) 防嗅探
嗅探是指第三者可以通过软件或硬件监听到网络传输的具体数据,比如我们用wireshark可以看到HTTP协议传输的明文,或者charles也可以。
HTTPS使用对称加密的方式将数据加密,比如AES对称加密,客户端在发送数据前先用密钥将数据加密,服务端收到数据后用同一个密钥解密。
有好奇好问的同学就问了:”那这个密钥是从哪儿来的呢?服务端怎么知道客户端用的密钥是什么?即使服务端收到客户端发来的密钥,服务端怎么辨别是不是假冒的客户端?”这就牵扯到HTTPS协议中最重要的证书认证了。
c) 防中间人
如果不采取任何措施,那么上一节种客户端给服务端发送密钥时,很有可能被劫持,中间人给服务端发送伪造的密钥,这时,客户端把中间人当做服务端,服务端把中间人当做客户端。
为了安全,我们决不允许该情况发生。同样的,HTTPS也不允许,它引入了数字证书的概念。
在客户端与服务端建立HTTPS连接时,服务端先给客户端发送包含自己公钥(非对称加密)的证书,客户端验证证书属实后,生成一串随机的密钥并利用证书中的公钥将其加密,发回给服务端,如果服务端的私钥能解开,则拿到了一份真实的没有被伪造的客户端密钥。
假设客户端给服务端发送密钥时被中间人拦截,由于中间人没有私钥,所以无法解密,自然拿不到真实的密钥。
到这里可以有个小结:服务端已经能信任客户端,并且持有客户端的密钥,后续可以用对称加密的方式与客户端通信。
但是,客户端如何能相信服务端呢?客户端怎么知道证书的公钥不是假货?
这里引入CA证书的概念,只要客户端能从认证中心那里得知证书合法,客户端就信任该证书。
服务端在启用HTTPS协议之初,必须生成自己的公钥和私钥。服务端保存好自己的私钥,同时将公钥和自己的域名信息送往认证中心。认证中心通过种种手段确认域名确实是该服务端所有,便给公钥生成证书,并发给服务端。
证书生成的步骤如下:
1)生成证书的信息(包括证书签发时间、证书过期时间、签发机构信息、公钥、公钥对应网站域名等)
2)对证书信息进行摘要
3)用认证中心的私钥(注意:认证中心用的是非对称加密)对摘要进行加密,得到签名
4)将签名加入到证书中
客户端访问时,服务端便将证书发给客户端,后者校验证书是否合法。
证书校验的步骤如下:
- 客户端一般内置十几个认证中心的公钥,在识别出证书发放机构后,客户端尝试用其公钥解密证书上的签名部分,若解密成功得到摘要,说明该签名是认证中心生成。
2)用同样的摘要算法对证书上的信息部分计算摘要,如果此时得到的摘要与上一步中解密得到的摘要相同,说明证书信息与签名对应,进一步说明证书是认证中心所发。
3)校验证书中的域名是否是正在访问的网站,若是则将证书上的公钥当做服务端的公钥。
假设中间人伪造一个证书,如果没能通过证书校验,则客户端不会信任中间人的公钥。(如果客户端安装charles下发的证书,则charles可以给客户端下发自己生成的公钥,进而充当中间人,所以说,一般情况下不要随意安装别人的证书)
到这里可以有个小结:客户端相信服务端发送来的公钥,可使用该公钥来加密自己生成的密钥。
三、HTTP/2
3.1特性
二进制协议,HTTP/2将通信数据分解成帧,以帧的形式在连接中发送数据。一般说来,客户端与服务端仅会建立一个TCP连接(connection),在同一个连接上可以同时传输多个逻辑流(stream),每个流中都可以传输请求和响应,我们来看一下结构图:
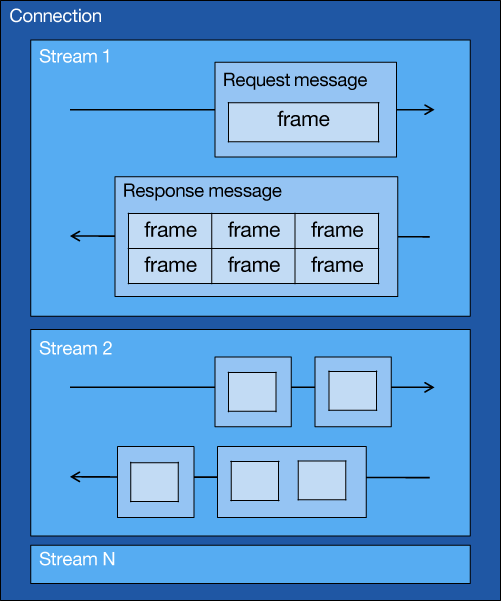
一个connection中容纳多个stream,stream可以并发交织流动传输,request message和response message被拆分成多个frame,放入特定的stream中传输,传输的单元变成了frame。下图演示浏览器和服务器之间是怎么传输帧的:
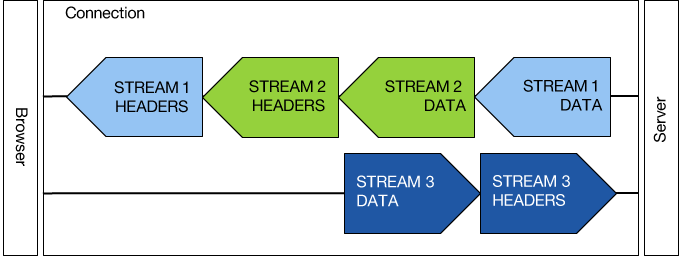
服务器通过2个流给浏览器传输2个响应,注意,第一个流有2帧,2帧之间并不是前后连接,而是插入了第二个流的帧,可见,帧的传输是很灵活的。
连接复用,从上面可以看出,HTTP/2能够在一个连接中随意地发送请求和接收响应,这是依靠给request加上唯一ID实现的。虽然HTTP/1.1有流水线管道技术,但必须等待响应回来才能发出下一个请求,存在线头阻塞问题,相当于串行请求,而连接复用相当于并行请求。
报头header压缩,采用类似字典的方式,仅传输新出现的header,这大大减少重复header造成的资源损耗(默认多个请求之间的header相同,除非覆盖)。
服务端推送,真正server push功能,比单纯轮询强大不少。
3.2 小结
HTTP/2最大的改变,无疑是二进制化。利用二进制化的帧实现完全的连接复用,降低延迟,还有流优先级控制等功能。
四、后话
虽然网站开启HTTPS和HTTP/2,用上连接复用这一神器,理论上比大多数网站要先进得多(哈哈),但因为网站是基于TCP协议和TLS1.2协议,前者有3次握手延迟和队头阻塞,后者有2次握手延迟和队头阻塞,初次访问与弱网环境下的用户体验仍旧不好。后面咱们可以升级TLS1.2至TLS1.3,减少1次握手延迟,响应加快100ms,采用更安全的加密方式,不过TLS1.3在去年8月份才正式推出,各大浏览器厂商的支持遥遥无期,至少目前尚未是通用的技术方案。
要继续优化网站的响应速度,咱们可以向谷歌学习,采用其QUIC协议*(可以把它看作是基于UDP实现的HTTP2),没有握手延迟,也没有队头阻塞,有更先进的拥塞控制算法,即使在弱网环境下也有很好的稳定性。从这也可以看出,谷歌确实是一家实力极强的值得吹一波的技术公司,在大部分厂商使用HTTP2时,谷歌开发并用上了新协议,即使是国内的腾讯这种老牌互联网公司,也只能基于谷歌开发出的QUIC做二次开发与维护。
另外,QUIC即将成为HTTP/3。搞笑,谷歌推出SPDY时,大家借助它推出HTTP/2,现在谷歌推出QUIC,大家又借助它推出HTTP/3,也许再过几年,谷歌会给人类贡献HTTP/4…